Unimelb Algorithms and Data Structures Assignment 2 Report
03/10/2025
Comparative Complexity Analysis of the Patricia Trie and Linked List
Introduction
This report aims to measure and compare performances of two bitwise structures implemented as part of assignments in Data Structures and Algorithms COMP20003. I will be comparing the growth of various factors. The number of bitwise comparisons is used as a measure of simple actions while the number of string comparisons will be considered a complex and therefore more expensive operation. Our ideal data structure should aim to minimise both bit operations and string comparisons. String comparisons should be kept to a minimum.
The number of node traversals is also considered since as linked structures, both the Patricia trie and linked list will suffer due to poor cache locality over contiguous structures used for dictionaries such as open-addressing hash tables. The ideal data structure will also minimise these pointer traversals.
Implementation Details
My patricia trie implementation is based on the original design proposed by Donald R Morrison which represents each node in the trie as either a leaf node containing the key or an internal node with two children and a "mismatchIndex" representing the bit index where the node's key differs from its parent.
typedef struct patriciaNode_t
{
struct patriciaNode_t* left; // next bit is 0
struct patriciaNode_t* right; // next bit is 1
// bit index where a node's key differs from its parent -1 if a leaf node
int mismatchIndex;
linkedList* record;
int recordCount;
} patriciaNode;This may differ slightly from Patricia Tries that store stemmed prefixes of keys at each node by using less memory and allowing for quicker lookups. However the implementation introduces additional complexity in implementation and requires full traversal of a single path in the trie during search. Additionally, I implemented a singly linked list to compare against.
typedef struct listNode_t
{
csvRecord* data;
struct listNode_t* next;
} listNode;
typedef struct list_t
{
listNode* head;
listNode* tail;
} linkedList;When comparing the trie and linked list I will be using the non-spellchecking variant to ensure fairness.
Hypothesis
Given our current knowledge of the time complexity of both Patricia tries and linked lists, I can make informed predictions related to the performance.
Patricia Trie
Let = number of nodes in the trie
Let = length of key in bits
| Operation | Sub Operation | Time Complexity |
|---|---|---|
| Insert | Search | |
| Insert | Bitwise String Comparison | |
| Insert | Find Bit Mismatch | |
| Insert | Insertion | (1) |
| Insert | Overall | |
| Search | Bitwise String Comparison | |
| Search | Get Bit | (1) |
| Search | Overall | |
| Query (spellcheck) | Search | |
| Query (spellcheck) | Bitwise String Comparison | |
| Query (spellcheck) | Get Leaves | |
| Query (spellcheck) | Check Leaves | |
| Query (spellcheck) | Overall | |
| Query (no spellcheck) | Search | |
| Query (no spellcheck) | Bitwise String Comparison | |
| Query (no spellcheck) | Overall |
Linked List
Let = number of nodes in the list
Let = length of key in bits
| Operation | Sub Operation | Time Complexity |
|---|---|---|
| Insert | Insert at Head | |
| Insert | Insert at Tail | |
| Insert | Overall | |
| Search | Traversal | |
| Search | Bitwise String Comparison | |
| Search | Overall |
From these theoretical complexities, I expect that while insertion will be significantly faster when using a linked list, Search and queries of the dictionary will grow far faster than that of a trie due to the linear time complexity.
On the other hand, all operations in the Patricia Trie are determined by the size of the key which could potentially result in slower runtimes with incredibly long keys. However it should be noted that a fundamental trait of the Patricia Trie is the ability to quickly skip bits and only check those that are relevant. This is due to Patricia Tries (and by extension regular Radix Tries) compressing common prefixes between keys.
Applying spellchecking will cause the time complexity to increase from to which is the same as that of the linked list.
Methodology
Our aim is to measure the performance of search operations in both a linked list and Patricia trie. So therefore we will only be counting operations that contribute directly to the search code. Even though the insert function in the Patricia trie does perform bitwise comparisons, string comparisons and node traversals, we do not count them.
Plotting
I created a list of structs to store the results of each query including the aforementioned operations and the key being searched. These structs are written to a CSV file which is then read by Python to generate our graphs.
typedef struct Query_t {
char* eziAdd;
int bitComparisonCount;
int nodeComparisonCount;
int stringComparisonCount;
int foundCount;
} Query;Results
Comparing Operations with Small Queries (1000)
All graphs have been log scaled.
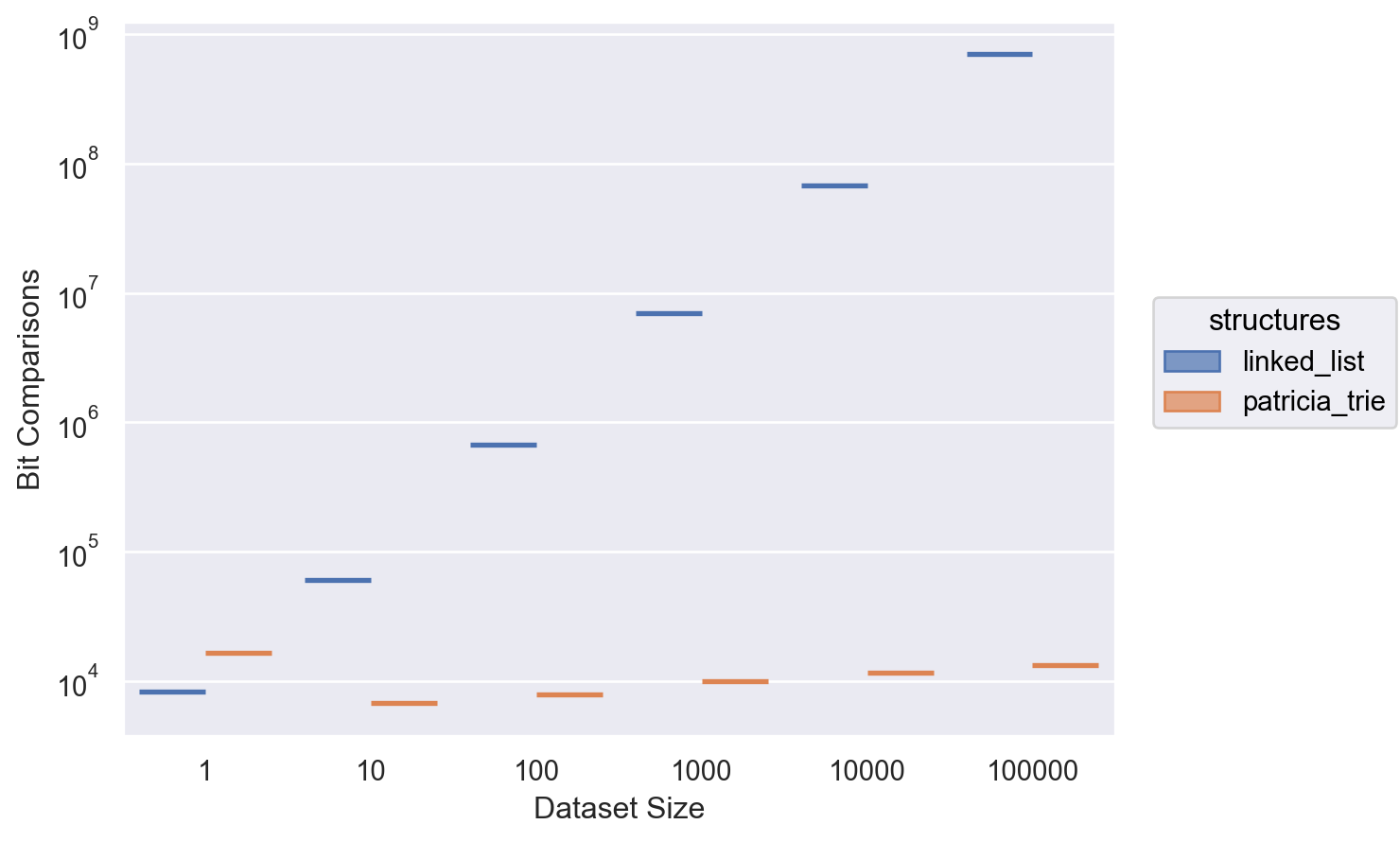 Bit Comparisons
Bit Comparisons
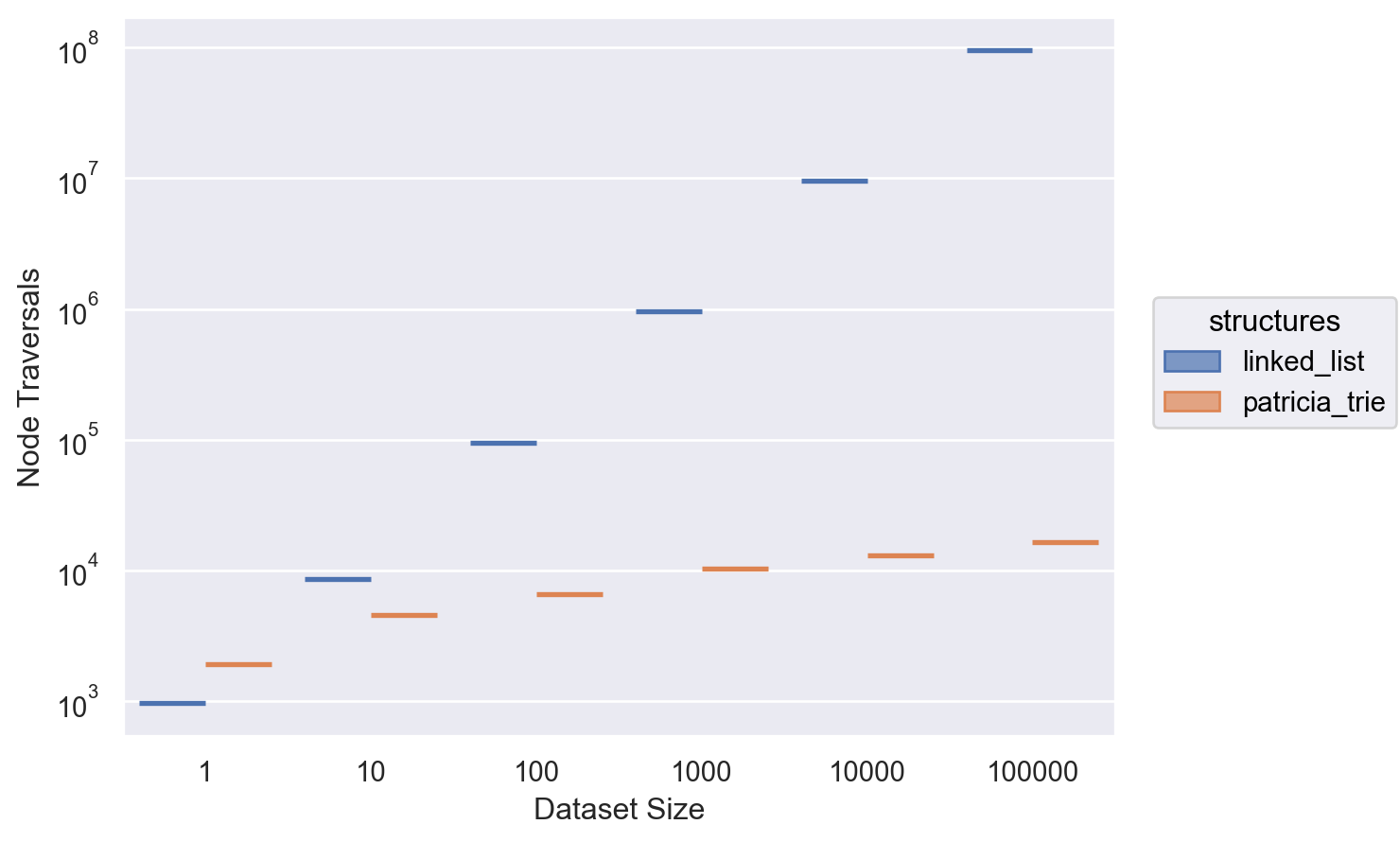 Node Traversals
Node Traversals
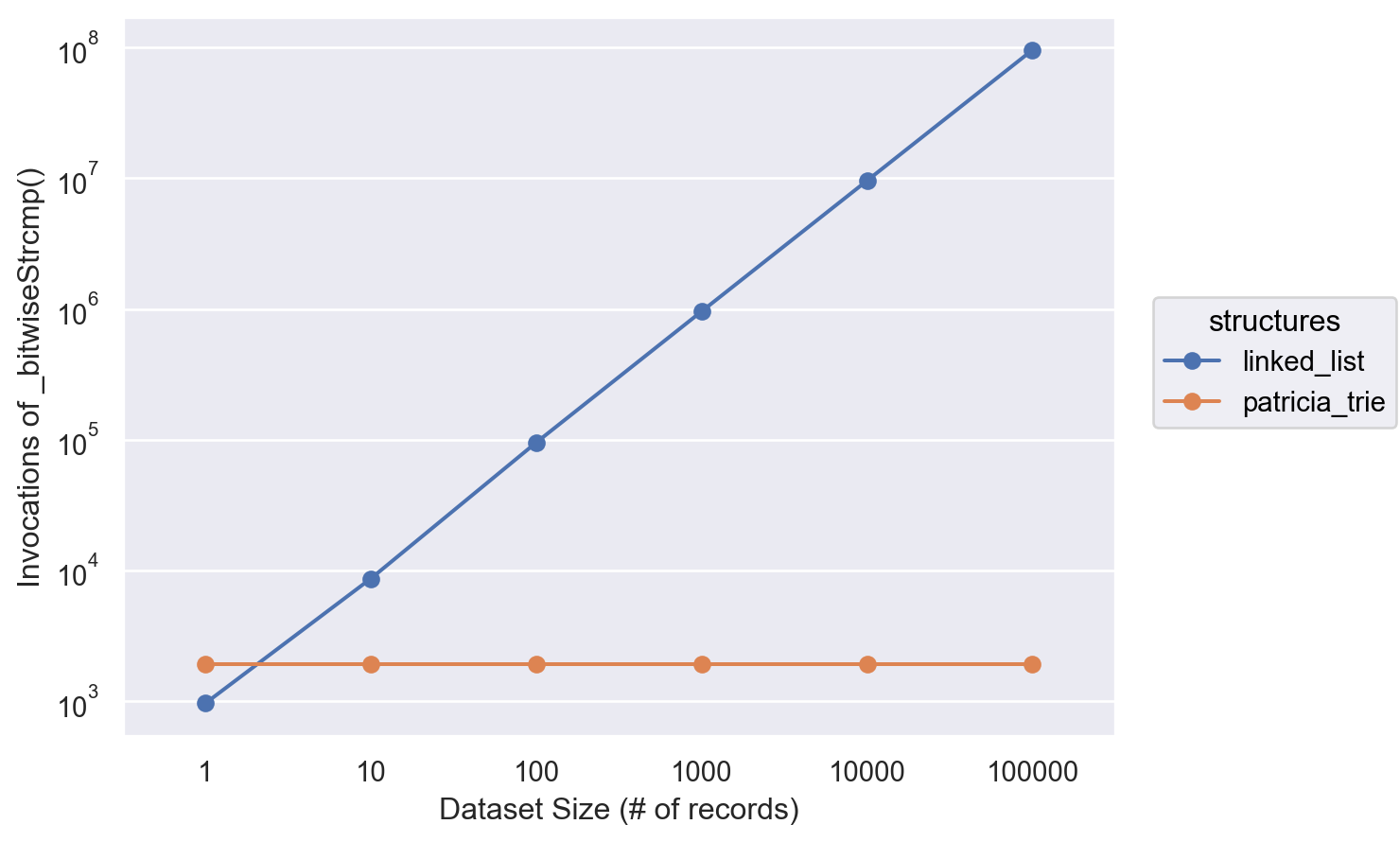 String Comparisons
String Comparisons
Analysis
Linked lists have a linear time complexity for all operations which is reflected in the graph incredibly well.
On the other hand, Patricia tries have a time complexity dependent on the length of their keys. This means that although the number of operations we do increase simply because we have more records to query, the number of operations increase at a far slower rate closely resembling that of a logarithmic function.
Node traversals show the same result with linked lists increasing at a linear rate while Patricia tries grow logarithmically.
The same story can be seen with our invocations of the bitwise strcmp function. Although interestingly,
this value remains the exact same for the Patricia trie compared to the linear growth of the linked list.
This is because the linked list will compare strings at every node whilst, the trie will only have to call it once
a single leaf node is found.
From these graphs we can immediately tell that the number of operations performed by Patricia tries grow far slower than that of linked list.
Additionally, due to their properties, we are also able to maintain a constant number of expensive string comparison operations. Our results immediately provide strong evidence that the Patrica trie is the superior data structure for this task.
Effect of Large Queries on Runtime
To further illustrate the impact of the linked list's linear complexity, I created a significantly input test case of 100,000 addresses.
I then timed my program using the time command. Once again, the graph is log scaled for better visualisation.
All programs were run on an AMD Ryzen 5 2600. I have a laptop with an I7-3632qm that I think would explode with some of the bigger tests.
data = {"size": DATASET_SIZES + DATASET_SIZES,
"data": [0.06, 0.1, 0.16, 1.32, 12.39, 324.84, 0.1, 0.07, 0.12, 0.13, 0.15, 0.35] ,
"structures": ["linked_list","linked_list", "linked_list", "linked_list", "linked_list", "linked_list",
"patricia_trie", "patricia_trie", "patricia_trie", "patricia_trie", "patricia_trie", "patricia_trie"]
}
df = pd.DataFrame(data)
(
so.Plot(df, x="size", y="data", color="structures")
.add(so.Line(marker="o"))
.scale(y="log")
.label(x="Dataset Size (# of records)", y="Elapsed Time (seconds)")
.plot()
)Once again our derived results align with our theoretical. While for incredibly small amounts of data, linked lists beat Patricia tries, increasing the dataset size causes the runtime for linked lists to increase nearly linearly.
Trying to Find Cases Where Linked Lists Can Work (Extreme Cases)
From the previous graphs, we have determined that for large amounts of data, the linear complexity of linked lists negatively effect performance and result in many unnecessary operations compared to Patricia Tries.
However as shown by the graphs, linked lists can be faster for very small amounts of data. Although this relationship ends after 10 items.
Random Data
I wanted to find a case where Patricia tries could exceed linked list in complexity. One ideas was to negate the main benefits of tries which are their ability to compress similar data.
So I created a dataset of 100,000 uuids to test this theory.
Observing the bit comparisons, I noticed all queries yielded a count of 296. Given that the bit count of a uuid generated in Python is 288 bits long and accounting for additional bit counts, this revealed that the Patricia trie was being forced to traverse its entire branch to find a key.
The runtime reflects this with an average of 0.7 seconds being recorded - nearly double that of our 100,000 address dataset.
Despite this, the Patricia trie was able to significantly outperform the linked list in both runtime and the number of operations. Although the Patricia trie performed slower, the linked list still performed even slower with a runtime of 3 minutes.
While high entropy data can slightly slow down Patricia tries due to being unable to compress similar keys, they still outperform linked lists by a significant margin.
Effect of Spellchecking (It's bad)
All tests previous were done with spellchecking switched off for the Patricia Trie to ensure a fair comparison. However the process of collecting leaves as candidates for spellchecking along with the spellchecking function increased the runtime significantly.
When finding candidates for the spellchecker, if the value differs enough the trie will be forced to perform the editDistance function on every single leaf in the trie. I generated a new set of UUIDs to ensure the spellchecking function would be tested.
The result was an incredibly slow runtime of 2 hours and 56 minutes due to each UUID resulting in the edit distance function being performed on every other node in the trie,
While the linked list was able to run faster in just 4 minutes and 22 seconds, it still performed far more bit operations than the Patricia trie.
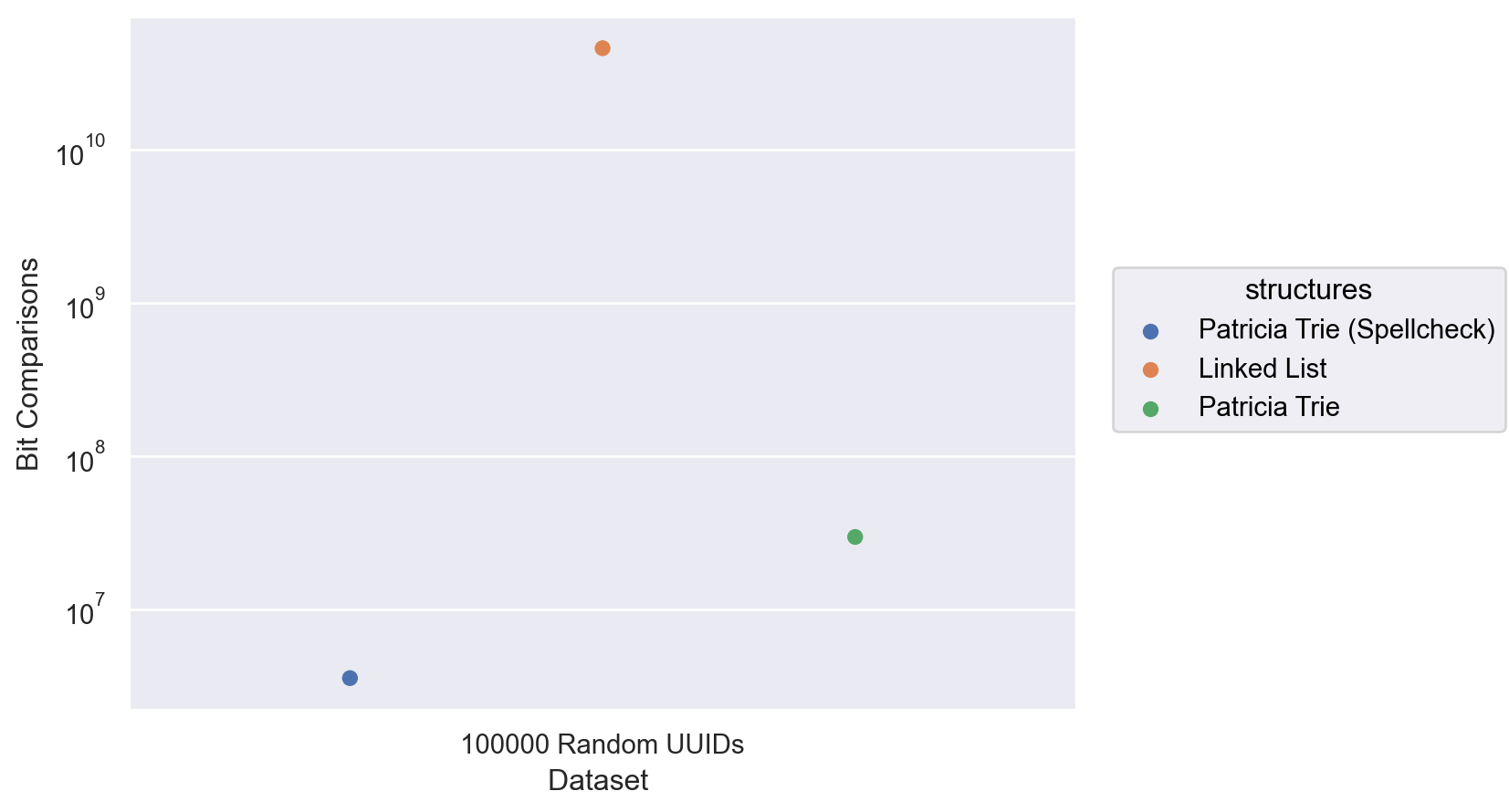
After seeings the result, it is clear that even in a manufactured scenario designed to work against the spellchecker. Its (approximately) logarithmic search complexity still beats the linked list without spellchecking.
With spellcheck, even if the runtime increases dramatically, the linked list still performed far more bit operations. Even with the increased runtime caused by spellchecking, Patricia tries still prove themselves to be more efficient structures.
Long Keys
The time complexity for searching a Patricia trie is theoretically defined as where is the number of bits in the key being searched. I wanted to test if increasing the lengths of keys would have a noticeable effect.
Using a new dataset of 100,000 long (1000 character) strings inspired by DNA sequences.
Interestingly I found that insertion took far longer which I believe was due to the call to search which required a traversal of the entire trie each search.
The overall program took 103 seconds to run. This pointed to our Hypothesis being correct and the runtime of the Patricia trie, depended more on its keys rather than the amount of data.
The linked list ran for an incredibly long time indicating to me me that the length of keys also contributed to the runtime.
Short Keys
Although the keys were long they did tend to differ slightly. To eliminate the possibility of the high entropy of keys playing a factor, I generated another dataset with incredibly short (10 character) keys.
Insertion and searching the patricia trie was hastened dramatically achieving a runtime of 0.7s.
From this I could conclude that, aligning with our theoretical expectations, the length of the key does affect the runtime of patricia trie operations.
Behaviour from the linked list also aligned with predictions. With a runtime of 4 minutes and 13 seconds, while it was significantly faster than the longer keys, it shows that even with short keys, linked list are limited by their linear search complexity and have no way of skipping unnecessary work therefore increasing the runtime.
Sorted Data
Sorting the data before inputting it did not yield any interesting results. Linked list searching remain unaffected as the entire list needed to be traversed and the Patricia trie would put the sorted data into a different order suitable for a trie.
No meaningful results were derived and the results were basically the same as my tests on unsorted data.
Many Duplicates
I briefly considered the idea of creating another dataset containing many duplicates however I decided not to test that since the structure of the Patricia trie meant that duplicates would simply be compressed into a single node whilst increasing the size of the linked list. This would only further help the Patricia trie's case as searching would theoretically be faster.
Conclusion
Linked lists are simpler to implement and in some cases may even out perform the Patricia Trie on small datasets. However when scaling to non-trivial amount of the data, the linear runtime of the linked list begins to slow it down significantly compared to Patricia Tries.
Patricia tries, while more error prone due to their increased complexity, scale far better than linked lists in the context of a retrieval system. Due to their ability to skip over many nodes therefore reducing node traversals, they are able to achieve far quicker runtimes.
Patricia tries do have caveats namely that their insertion can be significantly slowed down by incredibly long key lengths or high entropy data.
This means that Patricia tries may not be useful as a way of In the context of a web server, if designing a dictionary to map user IDs to access tokens, a Patricia trie may not be the ideal solution as the high entropy of unique user IDs will reduce the effectiveness of search as keys cannot be compressed.
Moreover, storing incredibly long keys would not be ideal for Patricia tries due to long insert times. That being said, querying is incredibly fast once all data is inserted.
However despite this, without expensive auxiliary operations such as spellchecking, Patricia tries remain an incredibly efficient (though slightly more memory intensive) way of querying low to medium entropy data over linked lists.
Linked lists are fundamentally bad as a store for quick retrieval. Even with testing extreme examples of data, I could not find a situation where a linked list could be used as a dictionary for a non-trivial dataset.
However despite this, linked lists still have their place. Due to the their near instant insertion, utilising linked lists when implementing a storage for data is preferable over the complexity for Patricia Tries. For creating dynamically sized arrays without the overhead of resizing, linked lists are a suitable data structure, however for non-trivial querying systems, trie based structures such the Patricia Trie should be used instead.